· Tomasz Guściora · Blog
Snack-size RAG - Guardrail Garage #003
A small, practical plan for building a snack-size RAG assistant with a tiny local LLM on a VPS. Goals, constraints, and a quick tour of RAG options, plus a few personal updates.

Snack-size RAG - Guardrail Garage #003
Thanks for your patience. I have been a bit overwhelmed by life lately. I am doing what I can to reset and return to regular posting, so bear with me and keep your fingers crossed.
I hope you enjoyed the last post about Claude Code. This time we are changing gear - starting to sketch prototypes, or at least planning the start.
Retrieval Augmented Generation (RAG)
Large language models are trained on vast internet data and allow us to access a lot of information quickly. But if you ask a chatbot about your company policy or your personal files, there is a good chance the model has no idea about them (if it did, that would be worrying). Sometimes it will admit, ‘I have no idea what you are asking.’ Other times it will confidently hallucinate.
Early attempts to close that gap focused on stuffing extra context into your message, for example:
Hi, I need to know where the nearest woods are.
### Context
I am building a sturdy and mighty trebuchet. I have an axe and I need construction materials (The content is not offered as legal or professional advice for any specific matter. Children, do not do this at home!)You enrich the prompt to help the model answer more accurately.
But we quickly hit a couple of walls:
- Copying and pasting relevant context into the prompt each time is cumbersome and not much fun.
- Context windows are finite - attach a 100-page PDF to every prompt, then ask about something else, and you will struggle to get accurate, grounded answers.
Fortunately, we do not have to leave everything in the hands of an LLM. We can programmatically add services that store lots of context and retrieve the relevant bits on demand.
That is how Retrieval Augmented Generation (RAG) was born. In a nutshell, it is a toolkit that enriches the user prompt with relevant information so LLMs can answer better.
Examples:
- You ask about company policy on Hawaiian pizza - before answering, the LLM checks official HR docs, retrieves the right paragraphs, and tells you it is a hard no-no.
- You tell your company sales assistant you are visiting Mr Marsellus Wallace to sell pizza ingredients. With help from RAG, the LLM notes that your profile prefers cynical answers and also notices a few pipeline items are paid and ordered but not yet delivered to Mr Wallace. Combined, that yields an answer suspiciously similar to this video1.
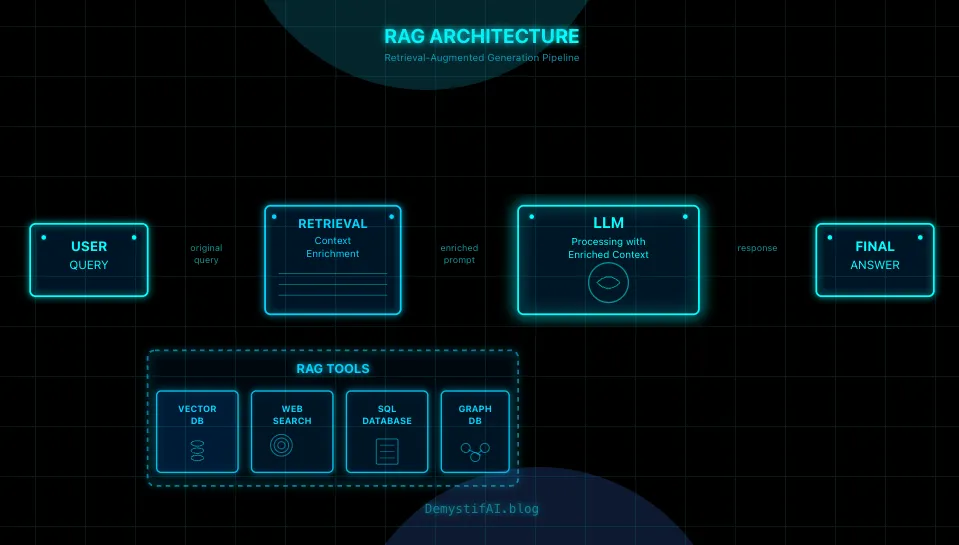
RAG, RAG everywhere
There are many flavours of RAG. During my learning in the Practical LLM course (which I have completed - DM me for the bank account number where I accept congratulations) we looked at an arXiv survey: Retrieval-Augmented Generation for Large Language Models: A Survey.
It was published in March 2024 and still lists 70+ methods. You could easily spend all your time just designing RAG.
But that is not what I want to do here.
If someone tells you ‘you need a vector database and equal-length chunking’ for any RAG, they might be missing your use case.
The first crucial step to a well-working RAG system is:
- Understand what you want to achieve - set a clear goal.
- Outline your constraints.
- Explore the solution space to reach that goal while respecting those constraints.
- Design the system (application).
- Implement an MVP (Minimum Viable Product).
- Test.
- Fix what testing reveals (there is always something).
- Stabilise the product.
- Repeat while expanding capabilities (new scope, features, resources - you name it).
If your system only needs to process pocket-size notes, you might not need a full vector database. Maybe simple embeddings and a lightweight store like .parquet are enough. Or even simpler - no embeddings: equip your RAG with a file or text search tool like grep.
For larger documents, chunking (splitting into smaller parts) might be necessary, but try to minimise context loss. Imagine splitting a book into sentence-length chunks: any idea longer than one sentence will be hard to capture fully. So maybe go paragraph-length, or fixed length, depending on the content.
All these methods have trade-offs because the systems do not truly ‘understand’ or ‘remember’. We programmatically process data and hope we retrieve the right information into the prompt.
You can explore how chunking parameters affect text in this useful micro-app.
Commercial providers of state-of-the-art (SOTA) LLMs offer behind-the-scenes tools for documents uploaded into projects, gems, or assistants. Not everyone wants to pay a subscription for a tool that is not ideal. And if you have lots of documents, token costs add up quickly.
Sometimes you want something more local and tailored to your needs, and for commercial products or apps it might be too expensive to use commercial APIs.
And that is how an idea popped into my head…

Idea behind snack-size RAG
The idea is simple (and a fun learning curve): deploy a very small local model on a Virtual Private Server and test its chops as a knowledge-base (RAG) assistant.
A few benefits I see in this approach:
- Test the capabilities of small local models.
- Practice serving LLMs on a VPS (maybe with a dash of infrastructure as code).
- Use the programmatic data processing and structured output techniques from the Practical LLM course.
- Deploy a web interface where users can sign up and chat with their mini-documents. That should help me pass the 10XDevs course project requirements.
So what is my goal? Design an end-to-end RAG assistant application that showcases the power of small language models (or at least tests it).
What are my constraints?
- Model: a quantised version of Liquid AI’s LFM2 - 1.2B parameters and 731 MB of weights. The specific quantised model is here.
- Hardware: 2x mikr.us VPS with 4 GB RAM each (tiny and relatively cheap). The plan is to use the first VPS for inference only and the second for all other services and website traffic. Will it be enough? We will see. The app definitely will not be faster than a Lamborghini.
- Handle multiple users (tricky - because of RAM constraints I might be capped to one connection at a time, but let us see).
- Allow each user 5-10 MB of total space for knowledge-base files (.txt, .md, .pdf). At this stage, I do not plan to process anything beyond text.
And that is it for today. More of an idea post, but next week we will dive into planning the implementation in atomic changes using Claude Code and maybe a few other useful tools. Stay tuned.

Behind closed doors
It has been nearly a month since the last post. I will not lie - it was a wild ride.
I can officially say I have joined the Master of Lore team and even had the luck to give an interview (you can read it here). Startup life is a different beast and the speed of change is astonishing. It is also very rewarding and a great way to learn fast.
On top of that, I finished the intense AI Managers 2 and Practical LLM courses. Lots of new knowledge - now I need time to turn it into practice. I will definitely cover some of those topics in upcoming posts.
Last but not least, I will be speaking at DEV AI by Data Science Summit. If you want to hear my experiences with Claude Code and refactoring - come by. Message me and I will share a 20% discount code.
As usual, feel free to reach out if you want to discuss AI ideas or collaborate:
What is coming up next week?
I will expand on the development and implementation plan for the snack-size RAG application. And I will ask some robots for help with this task.
See you soon.
Footnotes
And if you have not watched Pulp Fiction yet, add it to your homework. ↩