· Tomasz Guściora · Blog
Tokenomics of Large Language Models - Gradient Street #003
A practical tour of tokenisation for LLMs. Why word-level fails, how subwords and BPE work, and what modern tokenisers look like, with tips and resources. Plus a brief personal update.

Tokenomics of Large Language Models - Gradient Street 003
You already know this part: to help machines grok language, we turn words into numbers. If we want meaning, we embed those numbers in a multidimensional space.
Standard word-level tokenisation (1 word = 1 token; often pre-processed to reduce variants) runs into big headaches.
This week, I will walk through an algorithm built to fix that. Buckle up.
Word-level vocabularies - how about ‘no’?
Say you want to roll your own embedding algorithm. You pick Common Crawl because it is vast and free to access1 (for research under fair use2). So you grab the latest available (at the time of writing) August 2025 crawl archive - a modest 115.1 terabytes compressed. Uncompressed? 424 terabytes. Wow, that is a lot of bytes.
You will definitely see a huge variety of words. The more words you have, the more extremely rare ones show up. Their frequency often follows Zipf’s law.
Zipf’s law says that if you sort items by frequency, the frequency of the n-th item is approximately inversely proportional to n.
Mathematically speaking:
Often-cited Brown Corpus counts:
So the 4th word would be roughly 6.9 / 4 ≈ 1.7%, etc. But even from the table you can see the 3rd word is not 6.9 / 3 ≈ 2.3%, so results are fragile and sample-dependent. The 50th most common word would be ~6.9 / 50 ≈ 0.14% frequency in the corpus3. Imagine how sparse the word matrix gets.
This is a rule of thumb, not a rigorous law (statistical tests might not confirm your corpora follow Zipf’s law exactly). Nevertheless, as Alfred Korzybski said - “A map is not the territory it represents, but, if correct, it has a similar structure to the territory, which accounts for its usefulness.”4 That gives us a decent intuition: blasting algebra over gigantic, sparse matrices is not the best use of compute.
Another angle is 1 character = 1 token. But then every word explodes into many tokens, compute goes up, and capturing meaning and long-range dependencies gets awkward. After all, how much of “queen” lives inside those two “e” characters?
So, the main problems with word-level tokenisation:
- Out-of-vocabulary (OOV) words - word unseen during training? It becomes
[UNK]. Tough to capture meaning when all unknowns collapse into one bucket. Find “incredibad” in a movie review? As a neologism, it likely was not in training, so it becomes[UNK]and loses nuance. - Big, sparse matrices - rare words are mostly zeros. Hello, Zipf. You can lemmatise or stem to reduce sparsity, but you lose potentially useful details. Also, computationally meh.
- Languages with lots of morphology - English is relatively tame. German? “Telefon”, “Telefonrechnung”, “Telefonrechnungsanschrift”. Word-level treats them as totally different tokens, even though they share a base. The model might discover the relation later, but you do not feed it that structure upfront.
People are clever and came up with better tokenisation.
How?
Submerge into the subworld of subwords
And do not forget to leave a sub!
The trick is to tokenise units that are “just right” - bigger than characters, smaller than words: subwords. (Or more literally, byte sequences - we will get there.)
If our dictionary is ["apple", "apples", "appetizer", "appetizers"], possible tokens could be ["app","le","s","etizer"].
Benefits:
- All four words share “app”.
- Token “s” flags plural.
- Encounter OOV “apply”? Tokenise “app” +
[UNK]and keep part of the meaning.
We get parameter sharing, and robustness to OOV. If we encode on UTF-8 standard bytes, that means 8 binary bits ( = 256 possible values, from 0 to 255), we can try to fit much more than only ASCII characters.
Cool, right?
Right.
Popular subword tokenisers:
- WordPiece in BERT
- SentencePiece (Unigram LM) in Google’s T5
- Byte Pair Encoding (BPE) from GPT-2/3 onwards (with variants)
You should read about WordPiece and SentencePiece, but I will focus on BPE. It is considered state-of-the-art and variants are used by most LLM providers (at least OpenAI, Anthropic, Meta).
So, what is Byte Pair Encoding?
It started in 1994 as a data compression algorithm5. In C. How many of you code in C? I do not. C++ was one of my favourite courses though - I liked it so much I took it for three semesters instead of one. Oops.
But enough chit-chat.
Byte me! Simple BPE tokeniser algorithm
What happens under the bonnet?
- Training data is converted to UTF-8 byte representations (vocabulary size is an input parameter).
| Text | UTF-8 decimal byte representation |
|---|---|
| h | [104] |
| hello | [104, 101, 108, 108, 111] |
| é | [195, 169] |
| café | [99, 97, 102, 195, 169] |
| 🤖 | [240, 159, 164, 150] |
In UTF-8, ASCII uses 1 byte. That is 8 bits with a leading 0 matching 0xxxxxxx. The x’s are binary, giving 2^7 = 128 combinations (0-127). Those are standard Latin letters.
Expanding to other Latin-script alphabets and diacritics uses 2 bytes, adding 1,920 signs (e.g., é).
Further expansion to Arabic, Chinese, and other non-Latin scripts uses 3 bytes, adding 61,440 combinations.
Last but not least, we have the rest - including the cornerstone of modern civilisation: emojis (🤖 + 🤖 + 🍆 = 💻). That is another 1,048,576 code points.
Total - 1,112,064 combinations used on the modern web. That lets tokenisers and LLMs learn from essentially all typed WWW data (to my knowledge).
So full vocabulary size for modern UTF-8 could potentially be 1,112,064. But all known byte codes are currently at around 130 000. We need more emojis to fill the void people!
For those that did the math - you might wonder why there are only 1,112,064 combinations and not more? Well, that’s because UTF-8 standard has certain static bytes for each category (as you saw with ASCII static leading 0). That leads to easier categorization, however less base available (but at ~11,7% utilization of current available options who cares).
- The algorithm counts byte pairs and merges frequent pairs into new tokens.
Assume our training data is just 3 words: “lower”, “lowest”, ”newest”.
The algorithm will:
- do initial segmentation - decode words to UTF-8 byte representations. Here it is ASCII only, so 1 letter = 1 byte = 1 token
- calculate frequencies of token pairs
- merge the most frequent pair into a new token. Here “w” + “e” (3 occurrences - “we” is part of each of our three words) becomes “we” (with a new token id)
- represent words using the new tokens
- repeat until stopping criteria are met
If our stop criterion is 5 iterations, the loop might go:
- merge “w” and “e” (3x) into “we”
- merge “l” and “o” (2x) into “lo”
- merge “lo” and “we” (2x) into “lowe”
- merge “s” and “t” (2x) into “st”
- merge “lowe” and “r” (1x) into “lower”
End result:
- lower - “lower” (1 token)
- lowers - “lowe” + “st” (2 tokens)
- newest - “n” + “e” + “we” + “st” (4 tokens)
Instead of total 17 tokens (17 letters total with 1 token per letter), we end up with 7. That is 2.43x compression. Nice.
Also notice the vocabulary is growing - after 5 merges we added 5 tokens, so total size is 261.
More merges = bigger vocabulary.

Big-tech tokenisers
How different are these from the toy above?
Try these:
- Official OpenAI tokeniser
- Fan-made Anthropic tokeniser
Our tokeniser? 261 tokens total. OpenAI’s?

As you can see, OpenAI tokenisers have larger vocabularies. There is a trade-off between dictionary size and inference speed, so covering “all” possible token merges is not the goal.
Also, training size matters - we used three words vs hundreds of terabytes from the internet. Not quite the same scale.
As you can see for newer tokenisers we can probably assume that they use most of 130 000 known UTF-8 byte codes and have 70 thousand of merged new token id’s on top of that!
One important note: you must use the same tokeniser for encoding inputs and generating outputs. Otherwise, the LLM will interpret token IDs differently (token IDs are not stable across tokenisers - nor should they be).
Enterprise-grade tokenisers use special tokens to signal boundaries, structure, or tool calls. Super helpful for learning when to start and when to shut up… ehrm, stop.
Example special tokens (IDs vary by tokeniser):
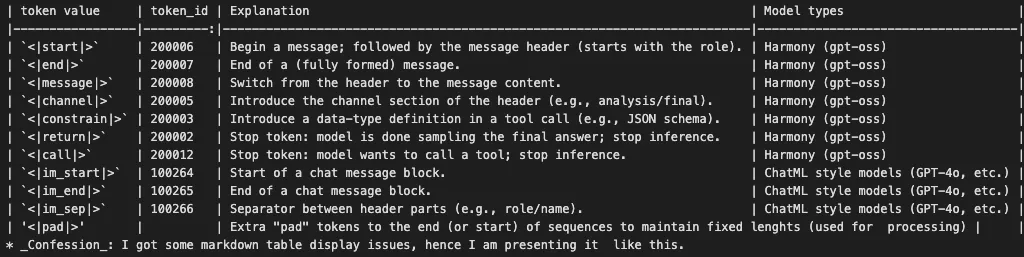
You can find more about Harmony tokens in OpenAI Harmony Cookbook.
Also, see supporting materials on tiktoken here.
Lastly, state-of-the-art tokenisers use regex for pre-tokenisation to recognise and split:
- numbers
- punctuation and symbols (
.,!) - whitespaces and line breaks
There is a lot of string pre-processing I skipped in the simple example.
Nevertheless, now you know the secret sauce for prepping training data. Use it wisely.

And yes, there is a Google Colab for you to play with. Hop on.
Behind closed doors
Ever think “I am my own worst enemy” - probably while eating ice-cream and Doritos and watching Bridget Jones or… Harry Potter?
Recently, I might be my own worst enemy. Not because I am doing anything dangerous - I just overbooked myself this month.
I am attending three courses (each five weeks of intense work) at the same time:
- Just started AI Managers 2 - hoping to sharpen business acumen around AI ROI, project evaluation, and networking. Goal: bridge the gap between AI tech and the C-level.
- 10xDevs 2 - an excellent course on pair programming with AI. Claude Code and Cursor for the win. I picked up a bunch of IDE and agent tricks fast - but there is still a lot to digest.
- Practical LLM from DataWorkshop - grounded and hands-on with validation and RAG. Tools like Pydantic and Instructor bring structure to LLM outputs (pun intended).
On top of that:
- I recently delivered a 2-hour talk at work about LLM capabilities and why we still need humans in the loop for most tasks. It landed well.
- I will run a full-day training for academic scientists on using LLMs to aid research (more bragging after delivery).
- I am collaborating on a business venture using LLMs in a very cool way. More on that in November.
So yeah - a lot is going on. Keep your fingers crossed for a high nerd-survival rate in October.
And that is why the next section will look a bit different for a couple of weeks.
As usual, ping me if you want to chat AI ideas or collaborate:
What is coming up next week?
Straight from educational hell. Next week will mark the start of a new series - stay tuned to park in Guardrail Garage.
I will share more practical tips on programming with AI and the tools I am using right now.
Do not worry - we will still cruise Gradient Street in future posts to unpack more of the secret sauce behind LLMs, step by step.
Keep on rocking in the free world Dear Friends!