· Tomasz Guściora · Blog
Do machines understand words? - Gradient Street #001
Do machines understand words? And if not exactly, do they use Google Translate?

Do machines understand words? - Gradient Street #001
You’ve probably talked with ChatGPT or Claude. If you feed it with a lot of contextual information, you might even get the impression that “it gets you”. Which, don’t get me wrong, I think is a great thing and enables a lot of cool uses (“Hey Chat, is this e-mail passive-aggressive? Please propose a nicer version, but let the recipients still subconsciously feel that I hate them”).
There is a lot of discussion over the internet do Machines really “understand” us or really “think”, but I won’t delve into that (they don’t, at least yet) much now, but one of the goals of this newsletter will be to equip you, dear Reader, with tools that will allow you to form an educated opinion on your own.
Crucial fact however - irrespectively of belief system - Large Language Models can support us with answers that are extremely useful.
This happens largely to evolution of a data science field called NLP - natural language programming.
And that’s what we will talk about today:
- what’s NLP
- what’s the difference between text understanding in games and in predictive models
- what are the simplest features convert text data into food for machine learning algorithms (yummy)
Hop on!
P.S. At the end you will find a link to Google Collab - when you can learn how to implement those methods and use them in Python on your own.
Dialogue in games vs text in NLP
If you are like me, you probably played a lot of computer games in your childhood, especially RPG’s (my favourite series - Baldur’s Gate and Fallout, however last Fallout I played was Fallout 3, so I am a bit of a dinosaur).
Now in those games you could engage in a lot of meaningful conversations. You had a lot of dialogue options and based on your conversation you could end up trading / fighting / you-name-it.
However under the hood mostly it was just a set of “if-then” instructions like (oversimplified to prove a point):
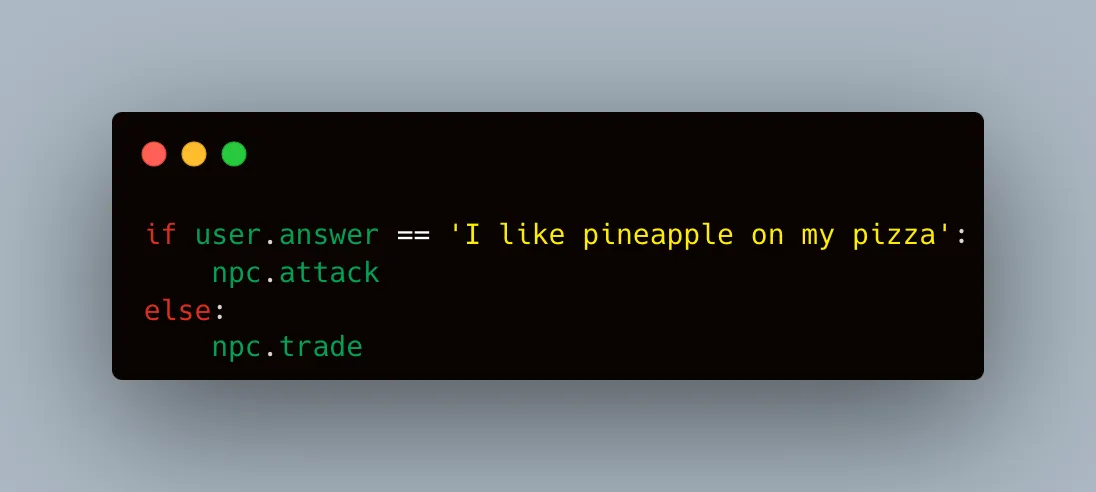
There is of course different, more reward-based system algorithms and reinforced learning when it comes to combat etc., but I’ll keep it short and sweet.
On the other hand we have raise of NLP - attempts to enable machine translation.
Based on sources we can track NLP origins to Leibniz1 (universal symbolic language of thought, one of fathers of the binary system) and Descartes2 (consciousness, machines and automata). Over time, with raise of Computer Science world saw more and more logical and rule-based language treatment (games, Turing Test, ELIZA3) and in 1980s NLP evolved to a more statistical / machine learning approach (thanks to a 2nd order effect of more compute availability). And we build on that up to this day - with transformer architecture and current GPT-family (General Pretrained Transformer) models like forementioned ChatGPT or Claude .
With bigger emphasis on statistical and machine learning methods - answers that we got stopped being deterministic (purely if-then) and started to be probability-based (for example if logistic model predicting ‘positive emotion’ in analyzed tweet would have a score of 0.98, which in this case would mean that the model estimates 98% chance that the tweet is positive according to it’s scoring function. I’m sorry - X.4). And because machine learning algorithms capture more and more intricate relationships between words and also we can feed them with more & more data (again - second order effect of more compute available) - answers and conversations with machines get more & more “real”.
Having said that - you can still find use-cases for very easy text transformations used as food for machine learning algorithms. And to kick-off this series properly - I’ll start with the simplest of them5.

One-hot encoding
Easiest way to transform text to numbers there is (I guess; you can prove me wrong). If a particular word exists in analyzed sentence / document - value equals to true. Otherwise false. So basically an easy binary variable.
In below example: S are sentences to analyse and each column name is a variable searching for a particular word (matching column name) in the sentence:

Now the last variable is “trebuchet” - rarely used anymore in modern day pizza-making as we can see from above sentences.
Advantages:
- simple
- for interpretable text mining - good feed into decision tree (capture combination of words that separate well a particular event, that you want to predict)
Disadvantages:
- doesn’t capture word relationships
- also very simple - doesn’t help you differentiate if you are going to get a free pizza or somebody ate your pizza
In a nutshell: basically this is what’s happening under the hood if you do one-hot encoding.
Bag-of-Words matrix
Increasing complexity by a notch.
Instead of binary variables we are creating a vectorised dictionary, in which you can store word-count of particular words.
Imagine translation of sentences like (bit of a tongue-twister for all my Italian friends) “I like pizza. Pizza is great with pineapples. Pizza, pizza, pizza.” to a matrix of values:
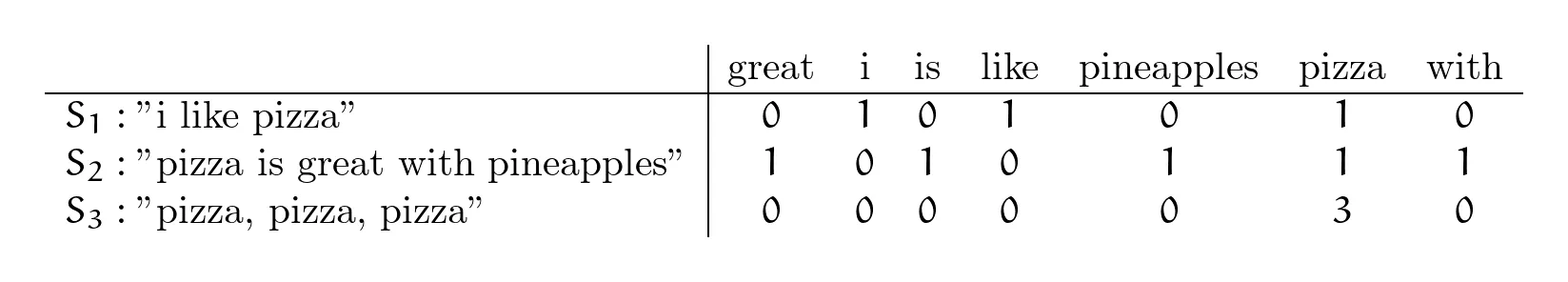
This time I am also capturing the number of occurrences of a word, so not only I know all the words in a sentence, but I know how frequently they occurred in a sentence (however you could modify your encoded variables from previous section to capture the number of occurrences as well). You can treat is as just a matrix representation of all one-hot-encoded variables.
Advantages:
- I know how many times a word got captured in analyzed piece of text
- I have a vector representing all possible word combinations
Disadvantages:
- Not really computationally effective for machine learning (large tables of mostly ‘0’ values for rare words)
- I don’t know anything about word relations, context or semantic meaning
TF-IDF score
Taking it up a notch again. In previous metrics I could look for occurrences of words in particular sentence, but I couldn’t capture relativity of this particular word to other words in the document. TD-IDF is relatively simple attempt at solving this challenge.
Score is represented by two sub-metrics: Term Frequency (TF) and Inverse Document Frequency (IDF).
Term Frequency (TF) - how often does a term t appear in the document d relatively to the total number of terms in the document:

Inverse Document Frequency (IDF) - logarithm of all documents D divided by number of documents containing the term t + 1 (to avoid dividing by 0). Logarithm is used to make value of IDF lie in a more manageable range.

TF-IDF score:
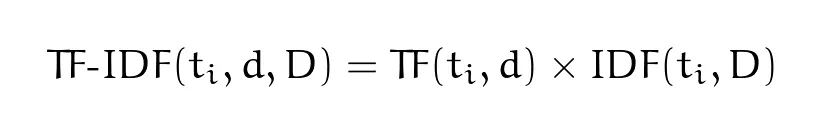
Let’s take our sentence and calculate TD-IDF using that formula6:

Trebuchet suprisingly still 0. But don’t worry Trebuchet, your time will come.
And now let’s use Scikit-Learn popular TD-IDF vectorizer6:

Error, error!
Why are the numbers are not matching?
This calls for Inspector Tomasz:
- First let’s look at official scikit-Learn TfidfVectorizer documentation. By default scikit-learn uses IDF smoothing and L2 norm for their metrics. Ok, let’s dig deeper.
- Going to scikit-learn feature_extraction github (here I would recommend LLM’s to do the heavy lifting of extracting and explaining the relevant code. Of course check if those explanations add up to the truth).
And after careful consideration I found that there are two main differences in formula implemented in scikit-learn.
First - to avoid dividing by 0 and bring values closer (but not completely) to the positive side for low number of documents (D), revised, smoothing-enabled TD-IDF formula looks like below:

Another thing is that scikit-learn normalizes the value using L2 norm:
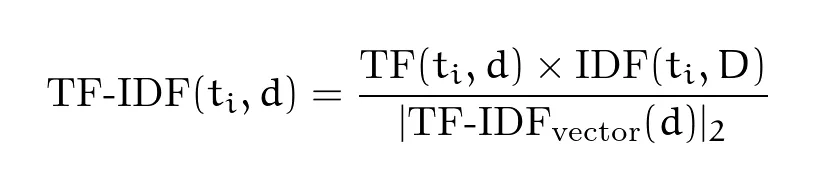
L2 Norm:
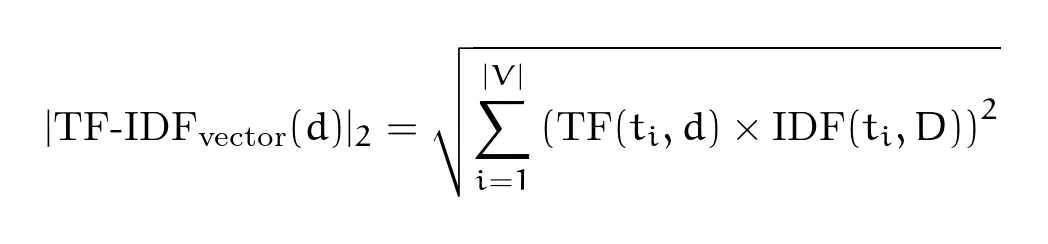
Where additional symbols mean: - = vocabulary (set of all unique terms) - = vocabulary size - d - document
Which is basically a squared root of all TF-IDF values for the words from vocabulary to the power of 2.
What are benefits of L2 norm?
- removes document length bias (i.e. documents / sentences with more words would have potentially larger TD-IDF values without normalization)
- metric is standardized across corpus (vocabulary) - this allows for consistent scale in place and comparable values
- Keeping normalized values to positive non-zero values allows for easier differentation and other mathematical operation, henceforth allows many machine learning algorithms to compute faster.
Now huge advantages of using TF-IDF metric:
- you capture not only words but also their relative weight to the whole document corpus
- you capture information about documents, not only words
Disadvantage:
- still no information about context and proximity of words (so order of words wouldn’t matter)
Important thing to be wary about: This is a technique that requires splitting data into train and test samples. If you will train your TD-IDF vectorizer on whole dataset and then only split data to train / test samples - you will commit information leakage (spilling information about test sample distributions to train sample), which can easily lead to overfitting.
Summary
I shown couple of easy, introductory NLP feature engineering techniques to prepare data in way, that it would be understandable for machines.
Below you have a link to Google Collab, that will allow you to implement those computations in Python.
Happy practicing!
Behind closed doors
A lot of time has passed since my last post (9th of December 2024).
But I wasn’t exactly sleeping during that time:
- I completely revamped my blog page using Cursor + Astrowind + Claude . You can view it here: https://demystifai.blog (it’s available in two language versions! - adding language switch button and preparing two versions of each text was the most time-consuming feature that I added ;))
- Got married in Las Vegas (no, it wasn’t a part of a bet ;) )
- Spend 35 days wandering around west USA
- Gained 6 kg of solid US weight total (and dropped 4 already, but still I believe that’s a pretty solid advertisement for case of American breakfast everyday ;) )
- obtained my Master’s degree with GPA of 4.62 (closing a thread from wayyy back ;) )
What’s coming up next week?
Next week I will teleport to the world of word embeddings - mathematical representation grasping semantic intricacies of words.
I’Il will go through Word2Vec and GloVe mechanisms.
Buckle up, it’ll be fun!

Footnotes
More background on history of NLP ↩
Remember! Fact that the model “thinks” or “rates” something with a particular score, doesn’t necessarily mean that this reflects reality in a close manner. Models estimate reality based on available data and simplified assumptions. ↩
Often for NLP task to use those simple methods I could stem or lemmatize words to capture different versions of 1 word as the same word, but I’ll skip covering this part here. You could read about it for example here ↩
For display reasons let me round those numbers up to third decimal place. You can view full digits in Google Collab. ↩ ↩2



